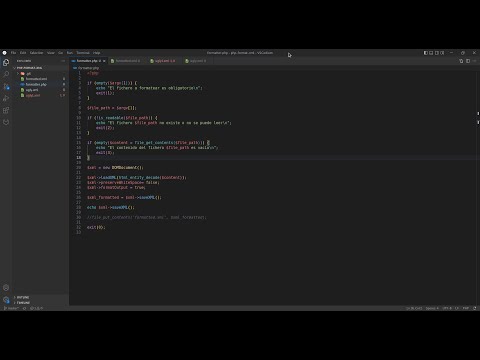
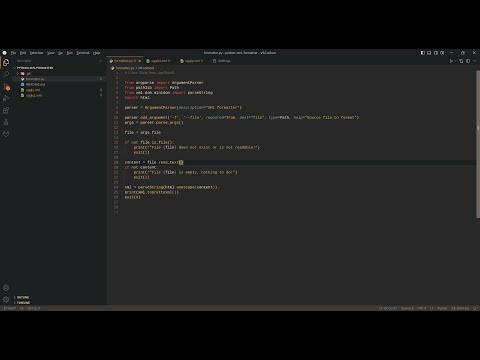
To format XML files usually I use option 3 described in How to pretty print XML on GNU/Linux but recently I've needed to work with XML files which in addition to being obfuscated one part of it use html entities, to start suppose we have an XML file like the this:
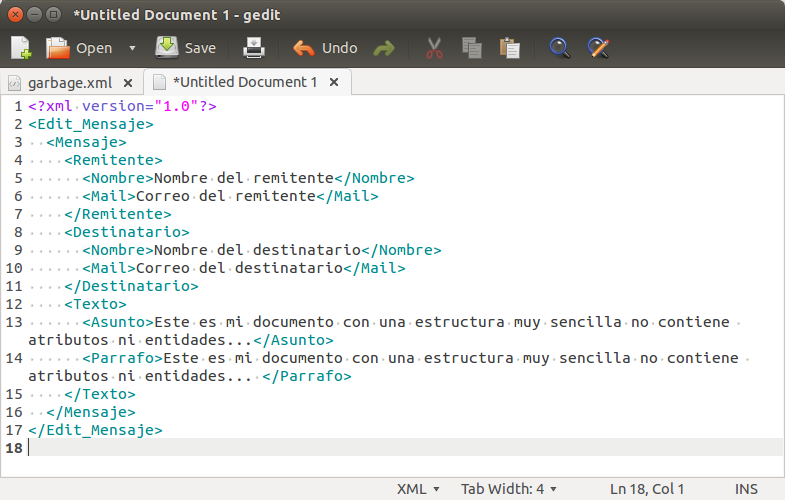
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE Edit_Mensaje SYSTEM "Edit_Mensaje.dtd" >
<Edit_Mensaje>
<Mensaje>
<Remitente>
<Nombre>Nombre del remitente</Nombre>
<Mail>Correo del remitente</Mail>
</Remitente>
<Destinatario>
<Nombre>Nombre del destinatario</Nombre>
<Mail>Correo del destinatario</Mail>
</Destinatario>
<Texto>
<Asunto>
Este es mi documento con una estructura muy sencilla
no contiene atributos ni entidades…
</Asunto>
<Parrafo>
Este es mi documento con una estructura muy sencilla
no contiene atributos ni entidades…
</Parrafo>
</Texto>
</Mensaje>
</Edit_Mensaje>Note: File retrieved from Wikipedia: Extensible Markup Language
but instead of having it as shown above have it in the following way:
<Edit_Mensaje><Mensaje><Remitente><Nombre>Nombre del remitente</Nombre><Mail>Correo del remitente</Mail></Remitente><Destinatario><Nombre>Nombre del destinatario</Nombre><Mail>Correo del destinatario</Mail></Destinatario><Texto><Asunto>Este es mi documento con una estructura muy sencilla no contiene atributos ni entidades...</Asunto><Parrafo>Este es mi documento con una estructura muy sencilla no contiene atributos ni entidades... </Parrafo></Texto></Mensaje></Edit_Mensaje>
Not very nice right? and we cannot apply the solutions offered in format XML files since the XML contains html entities so I developed a script in Python and then in PHP:
Scripts
Both scripts run the following logic:
- It reads the filename from standard input
- Check that the file exists and it can be read it
- It stores the contents of the file into a variable
- Decode html entities
- Format the XML
- Show the XML in an understandable format
Python script
#!/usr/bin/env python3
from argparse import ArgumentParser
from pathlib import Path
from xml.dom.minidom import parseString
import html
parser = ArgumentParser(description = 'Format an XML file')
parser.add_argument('-f', '--file', type = Path, dest = 'file', required = True, help = 'File to format/pretty print')
args = parser.parse_args()
file = args.file
if not file.is_file():
print(f"File {file} does not exist or is not readable!")
exit(1)
content = file.read_text()
if not content:
print(f"File {file} is empty nothing to do!")
exit(2)
xml = parseString(html.unescape(content))
print(xml.toprettyxml())
PHP script
#!/usr/bin/env php
<?php
if (empty($argv[1])) {
echo "El fichero a formatear es obligatorio\n";
exit(1);
}
$file_path = $argv[1];
if (!is_readable($file_path)) {
echo "El fichero $file_path no existe o no se puede leer\n";
exit(2);
}
if (empty($content = file_get_contents($file_path))) {
echo "El contenido del fichero $file_path es vacío\n";
exit(3);
}
$xml = new DOMDocument();
$xml->loadXML(html_entity_decode($content));
$xml->preserveWhiteSpace= false;
$xml->formatOutput = true;
$xml_formatted = $xml->saveXML();
echo $xml->saveXML();
//file_put_contents('formatted.xml', $xml_formatted);
exit(0);
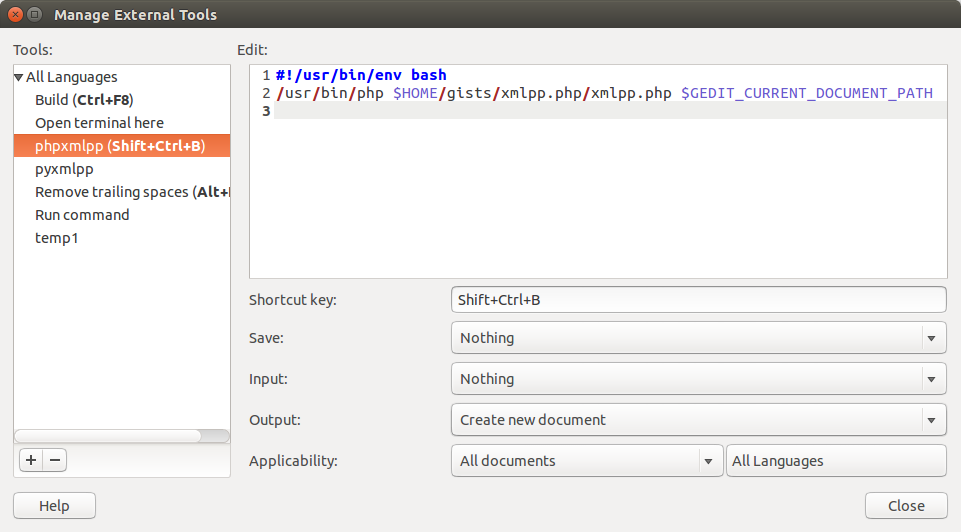
We can now integrate the previous scripts with gedit to do so (in this case will make it to the script developed in PHP):
- Run gedit
- Menu > Tools > Manage External Tool
- We add a new external tool and set the values as shown in the figure
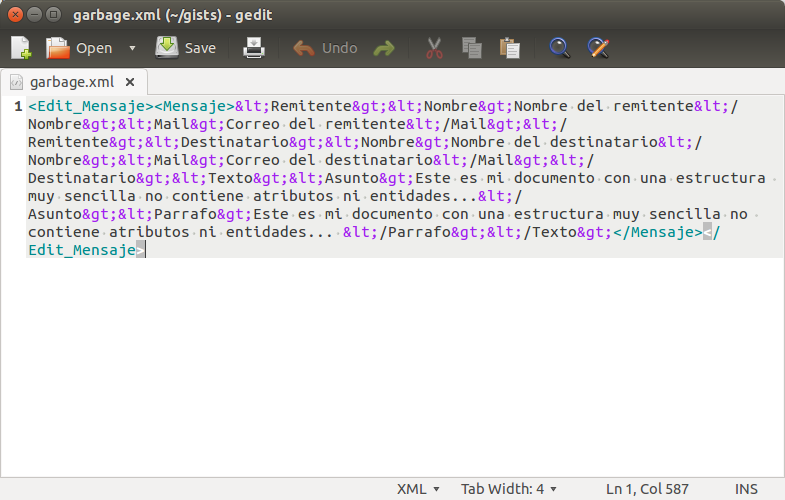
We opened our xml file which we call garbage.xml
We then format it using the combination of keys that we established when we integrate the external tools in the gedit as be shown in the figure.
Further readings